Some History

As humans went from hunter gatherers to agriculture, they settled down in small villages and hamlets. Once agriculture took care of food production, people could focus on specializing their skills – like being a shoe maker or a barber or an iron smith. They then bartered their services for food and products that they themselves did not produce. Next came the advent of money which brought about efficiency in transactions over bartering. After that came the industrial revolution with a large scale focus on mechanization. This was the era where machines powered actions that a human or a group of humans could not do and helped improve the efficiency of a single worker working in a job shop. This human history is very well documented in the Sapiens by Yuval Noah Harari.
The next level of efficiency was achieved by moving from “a job shop” production unit to an assembly line. Henry Ford is credited with introducing this innovation which brought about standardization and higher output. As production moved to assembly lines, there was the need to measure and standardize each action station to improve quality and throughput.
As industry specialized and process engineering became a science, data collection to fine tune processes whether to increase production or to reduce the cash cycle for a firm became important. Hence we saw industries investing in computing technology & resources. Now the trend is to not just eke out efficiencies, but to collect data from the environment or market to influence strategies on how to take advantage of these changes in preferences of consumers and to some extent even shape or mold user preferences.
How has the IT Industry Evolved?
Trends in Computing
Mainframe and Monolithic Architectures:
The first computers were large scale machines with very limited computing  power. These mainly were invented as an academic project which later found application in data crunching within industry. Initially only the largest industries could afford it, and run it. I am sure you would remember the punch card drives and the huge cooling towers around the mainframes!
power. These mainly were invented as an academic project which later found application in data crunching within industry. Initially only the largest industries could afford it, and run it. I am sure you would remember the punch card drives and the huge cooling towers around the mainframes!
Evolution of Distributed Systems & Client Server architecture:
Since the 80’s we have seen an explosion in the speed at which information  can be collected, processed and disseminated. Some advances came from the mainstreaming of IT into every business or organization. Initially the target was automation – simple enterprise systems that were automated for e.g. The production, planning, accounting, sales etc. There were a number of different flavors of distributed platforms that had specific appeals to different sets of users – the windows platform that was very popular in business user computing segment, the mac platform that appealed to an individual user with needs for creative art applications and the unix/linux platforms which appealed to the geeks. Eventually as we saw these platforms compete we saw the linux/java stack start to dominate the back end processing at most business enterprises, while the front end remained windows based and Apple made a big dent into the personal computing segment.
can be collected, processed and disseminated. Some advances came from the mainstreaming of IT into every business or organization. Initially the target was automation – simple enterprise systems that were automated for e.g. The production, planning, accounting, sales etc. There were a number of different flavors of distributed platforms that had specific appeals to different sets of users – the windows platform that was very popular in business user computing segment, the mac platform that appealed to an individual user with needs for creative art applications and the unix/linux platforms which appealed to the geeks. Eventually as we saw these platforms compete we saw the linux/java stack start to dominate the back end processing at most business enterprises, while the front end remained windows based and Apple made a big dent into the personal computing segment.
These led to centralized databases which facilitated the collection and analysis of historical data to make processes more efficient. A number of database structures evolved from network to hierarchical, then relational and object databases evolved as a result.
Web Infrastructure and Interconnection of computers
In the 90’s we had the development of the world wide web, with computers  forming a connected web, with standardized communication protocols like TCP/IP, HTTP, SMTP etc. This was a huge improvement to the unconnected islands that businesses and users had maintained prior to this. This really improved the velocity of information travel – from copying data to floppy drives and moving from computer to computer, to directly transmitting information from one computer to another when every node became addressable and ready to understand communication over standard protocols.
forming a connected web, with standardized communication protocols like TCP/IP, HTTP, SMTP etc. This was a huge improvement to the unconnected islands that businesses and users had maintained prior to this. This really improved the velocity of information travel – from copying data to floppy drives and moving from computer to computer, to directly transmitting information from one computer to another when every node became addressable and ready to understand communication over standard protocols.
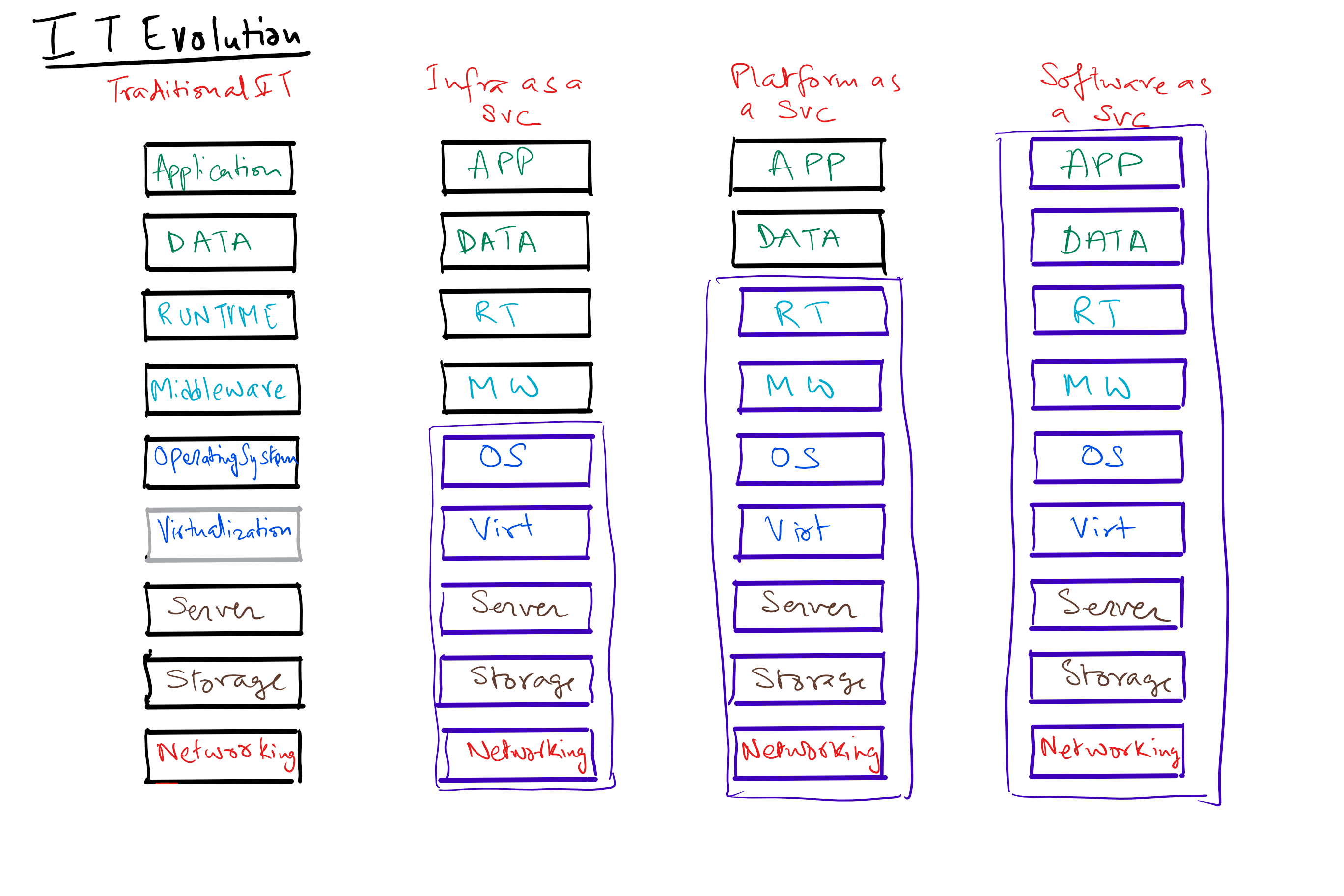
Development of Cloud Infrastructure:
In the 2000’s the trend moved to virtualization and the ability to run multiple processing slices on any physical machine. Computing became fungible and transferable. The idea was if every one was running their own physical servers which were not highly utilized, it would be better to have highly fungible compute and storage slices that could move around virtually to the least busy node, thereby improving efficiency multi folds for our computing and storage hardware.
processing slices on any physical machine. Computing became fungible and transferable. The idea was if every one was running their own physical servers which were not highly utilized, it would be better to have highly fungible compute and storage slices that could move around virtually to the least busy node, thereby improving efficiency multi folds for our computing and storage hardware.
IoT (Internet of Things)
We have also seen the shrinking of compute hardware to such an extent that  this hardware can be embedded in any device or appliance. So a washing machine or a refrigerator may have enough and more computing power as a specialized computer from a few years back, implies each of these devices are capable of producing process data that can be collected and analyzed to measure efficiency or even proactively predict failures or predict trends.
this hardware can be embedded in any device or appliance. So a washing machine or a refrigerator may have enough and more computing power as a specialized computer from a few years back, implies each of these devices are capable of producing process data that can be collected and analyzed to measure efficiency or even proactively predict failures or predict trends.
Decentralized Value Exchange:
A parallel development has been the paradigm shift in creating the ability to  transfer value instead of just information. This came about from a seminal paper by Satoshi Nakamoto and the origins of block chain (more on this in another post).
transfer value instead of just information. This came about from a seminal paper by Satoshi Nakamoto and the origins of block chain (more on this in another post).
Some call it a fundamental shift in philosophy where we do not need to  depend on a central store of value (or authority) to establish the truth. It tackles the double spend problem in a unique and novel way without relying on this central agent. This has spawned applications in various sphere’s like digital currency, money transfer, smart contracts etc. that will definitely change the way we do business.
depend on a central store of value (or authority) to establish the truth. It tackles the double spend problem in a unique and novel way without relying on this central agent. This has spawned applications in various sphere’s like digital currency, money transfer, smart contracts etc. that will definitely change the way we do business.
Big Data Computing
Today the amount of data has become so overwhelming that we find traditional centralized database architectures unable to keep up. This has resulted in a number of new architectures like Hadoop with its own map  reduce algorithms and its family of peripheral components/applications like HDFS (Hadoop Distributed File System), Hive (interpreter that turns sql into MR code), PIG (scripting language which gets turned into MR jobs), Impala (sql queries for data in an HDFS cluster), Sqoop (convert data from traditional relational DB into an HDFS cluster), Flume (injesting data generated from source or external systems to put on the HDFS cluster), HBase (realtime DB built on top of HDFS), Hue (graphical front end to the cluster), Oozie (workflow tool), Mahout (machine learning library) etc.
reduce algorithms and its family of peripheral components/applications like HDFS (Hadoop Distributed File System), Hive (interpreter that turns sql into MR code), PIG (scripting language which gets turned into MR jobs), Impala (sql queries for data in an HDFS cluster), Sqoop (convert data from traditional relational DB into an HDFS cluster), Flume (injesting data generated from source or external systems to put on the HDFS cluster), HBase (realtime DB built on top of HDFS), Hue (graphical front end to the cluster), Oozie (workflow tool), Mahout (machine learning library) etc.
Given this explosion of data that is being produced, collected, processed and acted upon which is beyond human capabilities, we have had to resort to delegating this to machines to collect, process and make sense of these trends – hence the renewed focus on machine learning and artificial intelligence.
Data Analytics and Usage of various Modeling Tools
Given the volume, velocity and variety of data we deal with, its humanly not possible for humans or organizations to analyze this steady stream of data and make sense of it. Hence we have started to construct models to analyze and make sense of this. There are a number of tools available that visualize and provide insights into this data and they inherently use a best fit model that is able to fit to existing data as well as provides predictive value to extrapolations of the causative variables.
make sense of this. There are a number of tools available that visualize and provide insights into this data and they inherently use a best fit model that is able to fit to existing data as well as provides predictive value to extrapolations of the causative variables.
This has become so ubiquitous in our lives that everything from credit scores to teacher ratings to how an employee is rated at work all depend on models. One of the critical insights in all this is that our inherent biases get encoded into these models. Hence we need to be careful to not trust these models without establishing their fairness. The best defense that we can employ is transparency and negative feedback control loops that help correct these models for accuracy. Cathy O’Neil has analyzed this very phenomenon in her book Weapons of Math Destruction – a delightful read!
Artificial Intelligence and Machine Learning:
Artificial intelligence is intelligence exhibited by machines. AI attempts to  solve the following categories of problems using various methods (statistics, computational intelligence, machine learning or traditional symbolic AI) to achieve goals like social intelligence, creativity and general intelligence.
solve the following categories of problems using various methods (statistics, computational intelligence, machine learning or traditional symbolic AI) to achieve goals like social intelligence, creativity and general intelligence.
- Reasoning
- Knowledge Representation
- Planning
- Learning
- Natural Language Processing
- Perception
- Robotics
There have been a number of efforts into machine autonomous behavior for  e.g. autonomous driving cars, that use a variety of sensors like cameras and radars to collect information about the road and other vehicles and make real time decisions about control of the car.
e.g. autonomous driving cars, that use a variety of sensors like cameras and radars to collect information about the road and other vehicles and make real time decisions about control of the car.
Machine Learning problems can be broadly divided into supervised learning (where we have a body of data that a computer can use to learn and mimic), unsupervised learning (where the computer tries to make sense of patterns in a sea of random data whether through classification or clustering) and reinforcement learning (when a program interacts with a dynamic environment to perform towards a certain goal without an explicit teacher). A general categorization of machine learning tasks are as follows – classification, regression, clustering, density estimation and dimensionality reduction.
Is the ultimate design the creation of a self aware machine that can compete  with humans for survival? Will this be a symbiotic relationship or a competition for survival? Are we simply a tool in the evolutionary process playing our part in creating a smarter, better and more resilient new being?
with humans for survival? Will this be a symbiotic relationship or a competition for survival? Are we simply a tool in the evolutionary process playing our part in creating a smarter, better and more resilient new being?

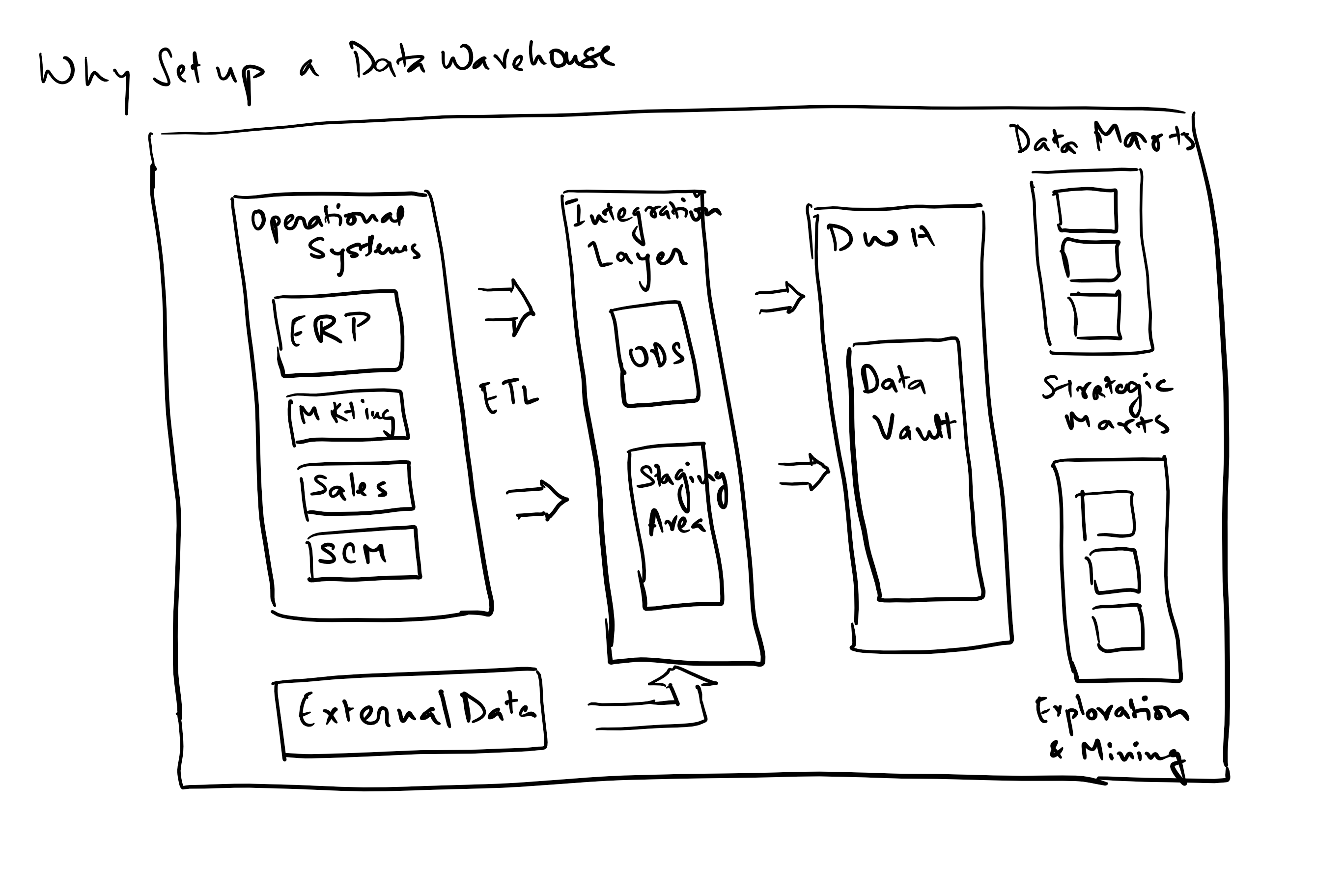
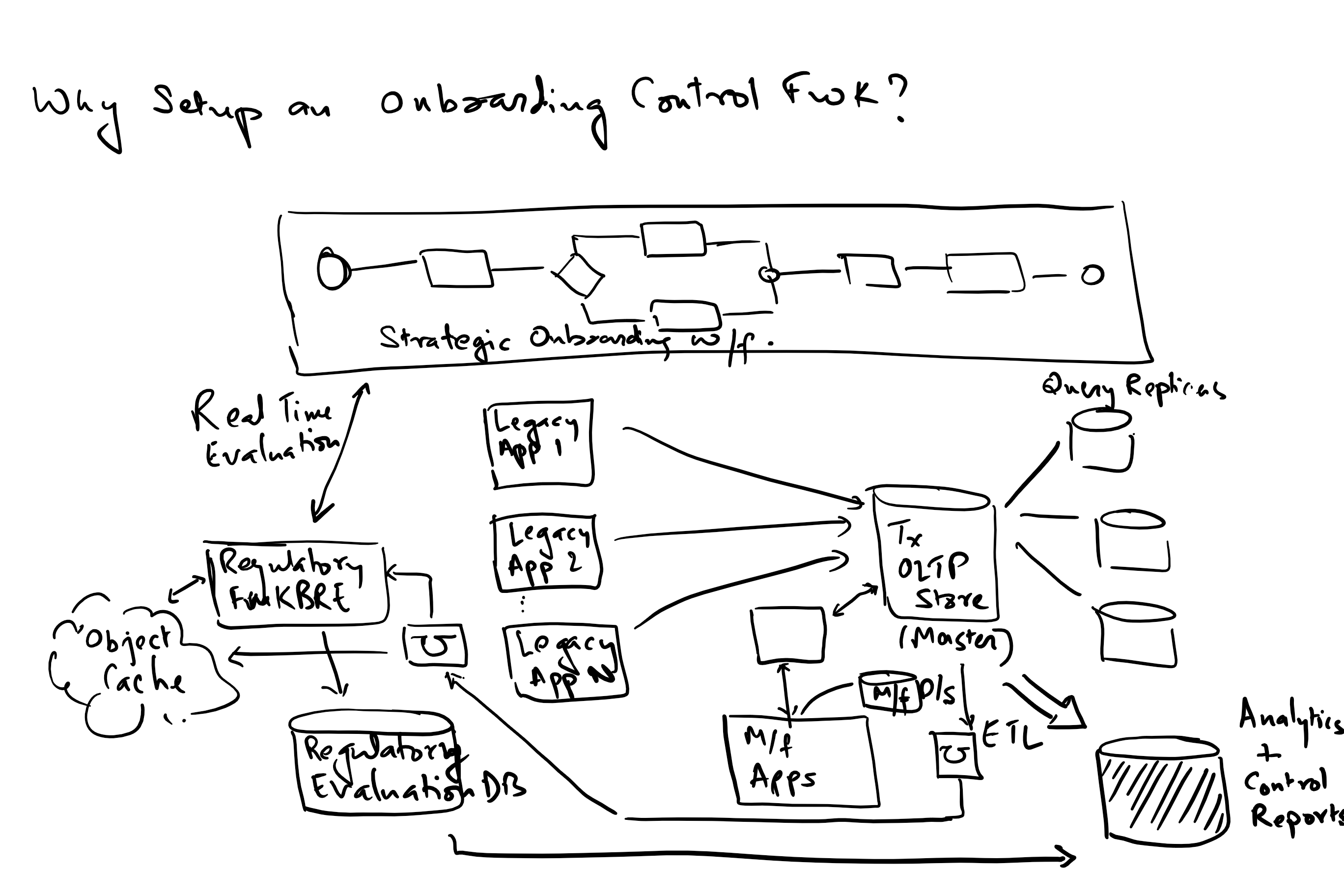


 Common measures that should drive an application or application development team’s metrics collection and measurement:
Common measures that should drive an application or application development team’s metrics collection and measurement: