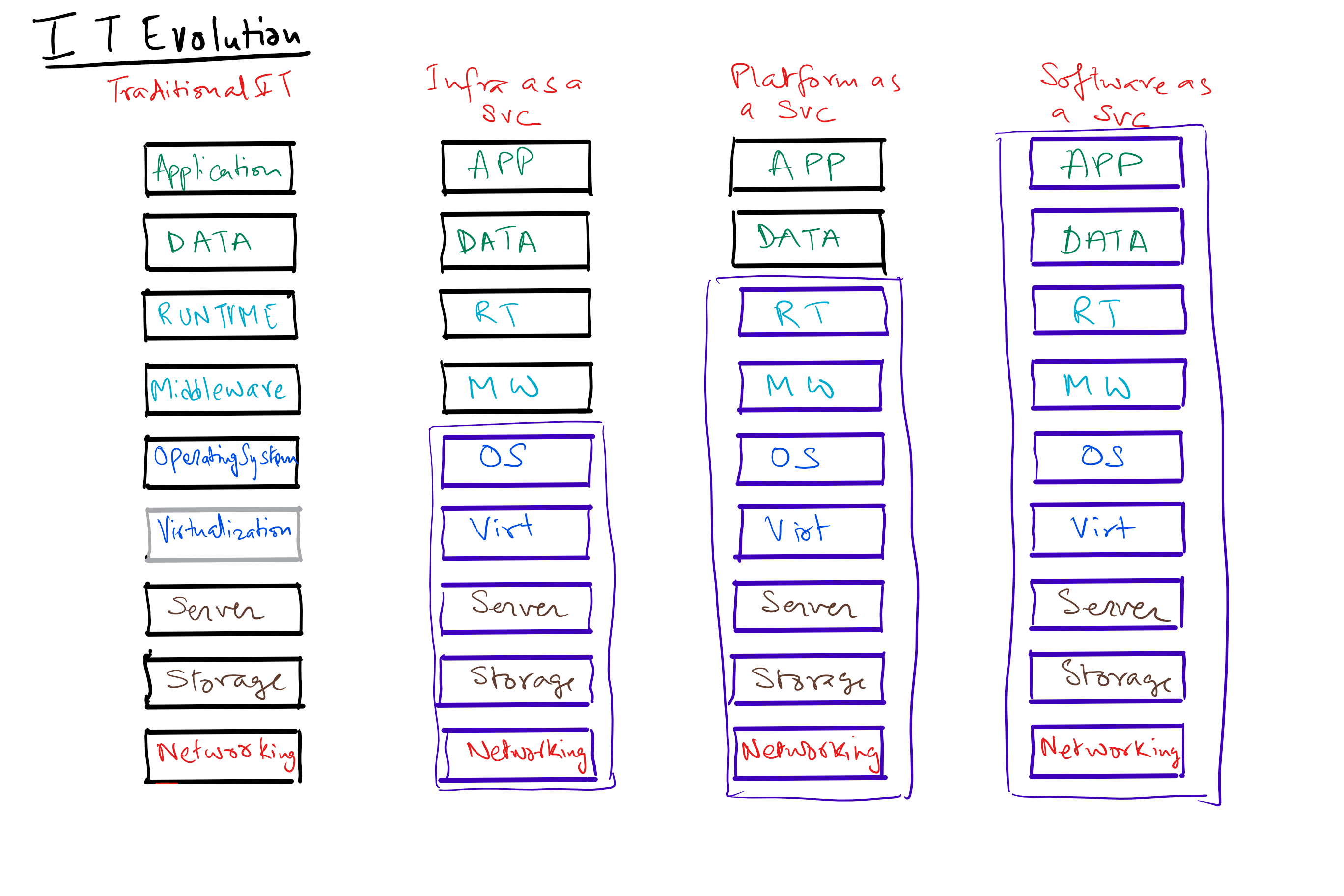
What is a Data Science Platform?
It’s a platform that allows for data collection, extraction, storage, exploration, visualization, inference & analytics and ultimately modeling to provide predictions and classifications.
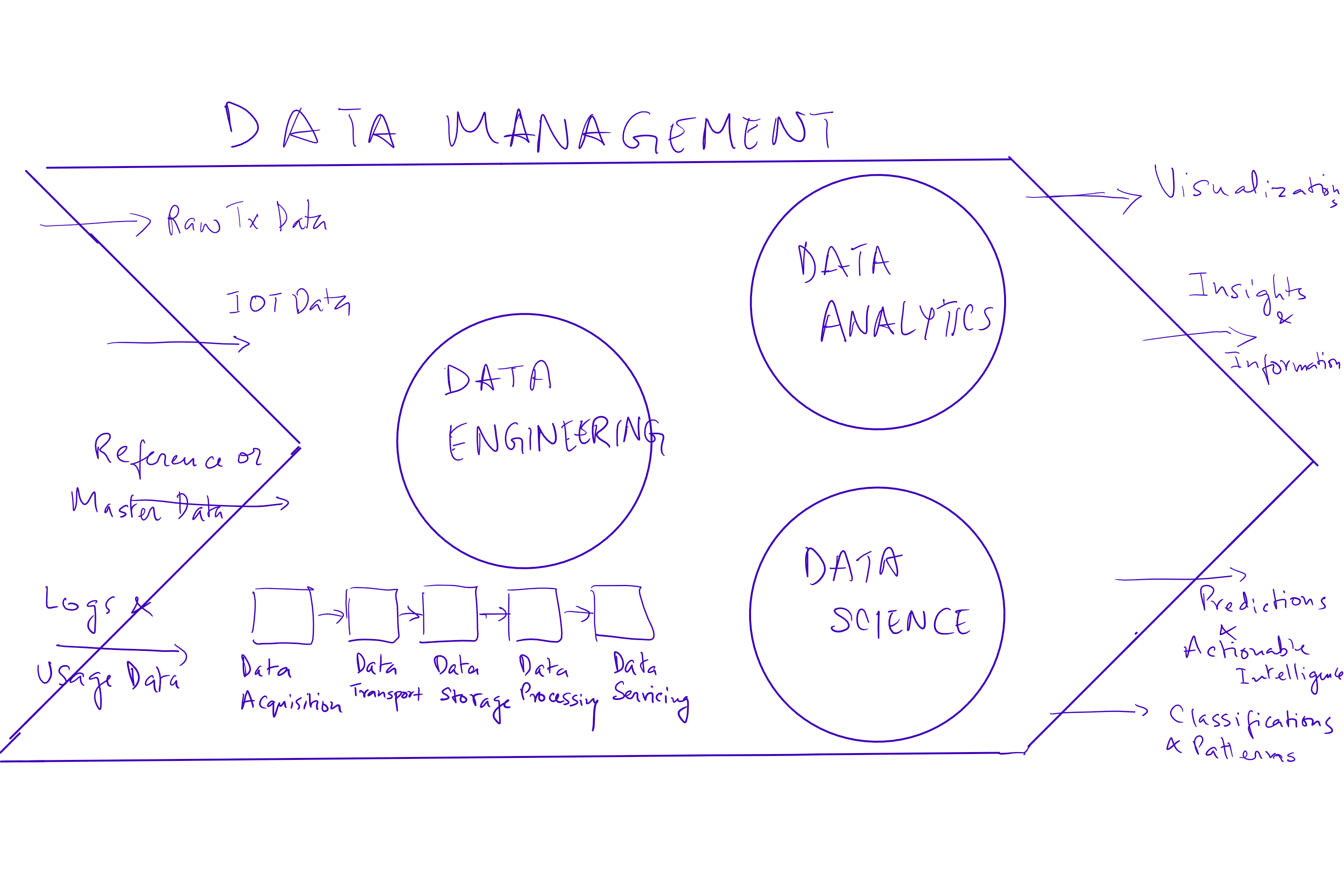 Why do you need a data science platform and what do you plan to achieve from it?
Why do you need a data science platform and what do you plan to achieve from it?
Usually the business need is to predict the future and establish causation. In order to predict the future one must determine independent and dependent variables, causation vs. correlation and thus come up with models that allow for predicting what the future will be when we tweak certain causative factors.
What are the key elements needed?
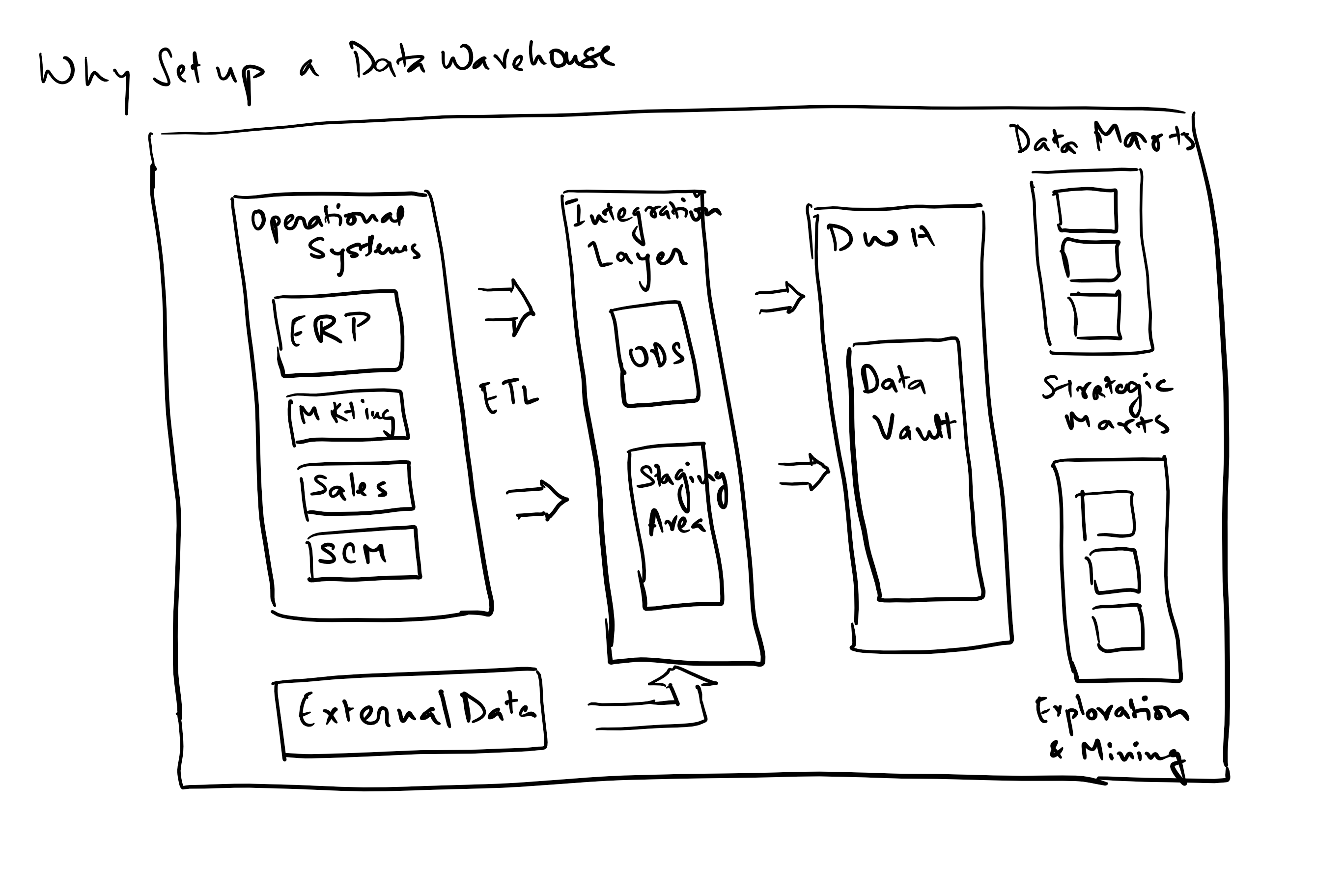
There are mainly three key elements of data management –
1. Data engineering – is the set of practices that convert raw data to processed data by building data pipelines, applications and APIs. This process is concerned with how data is captured, moved, stored, secured, processed (transformed, cleansed and aggregated) and finally utilized.
The different stages within data engineering are:
Data acquisition is the process of acquiring data with concerns around the format of source data, existing interfaces that are available or new ones that have to be built, security (including authentication, authorization and encryption), maintaining reliability and finally latency.
Data transport manages reliability and integrity in transport, security, latency and costs and bandwidth.
Data storage deals with the flexibility in storage, choices around schema and schema less storage, high availability and redundancy and cost of storage.
Data processing deals with transformation, cleansing, filtering, enriching, aggregating and machine learning models for prediction.
Finally, Data Servicing is the availability pattern to end consumers of the data, dealing with latency, redundancy and availability, consumer competency in understanding and utilization of these data sets, flexibility of schema and ultimately the APIs for consumer applications.
2. Data Analytics – Is the practice of using the data produced by data engineering to convert it into insights and information. The tools we currently use in this space are Tableau and Qlikview reporting packages.
3. Data Science – Ability to use analytics and insights to predict the future using data and patterns observed in the past. The work includes integrating and exploring data, building models using such aggregated data, extracting patterns in past data and finally presenting results either through reports or model-powered applications. Some of the key tools we have used on our platform are Jupyter and RStudio for ongoing algorithm development, Spark for distributed execution and Kafka for messaging and data acquisition.
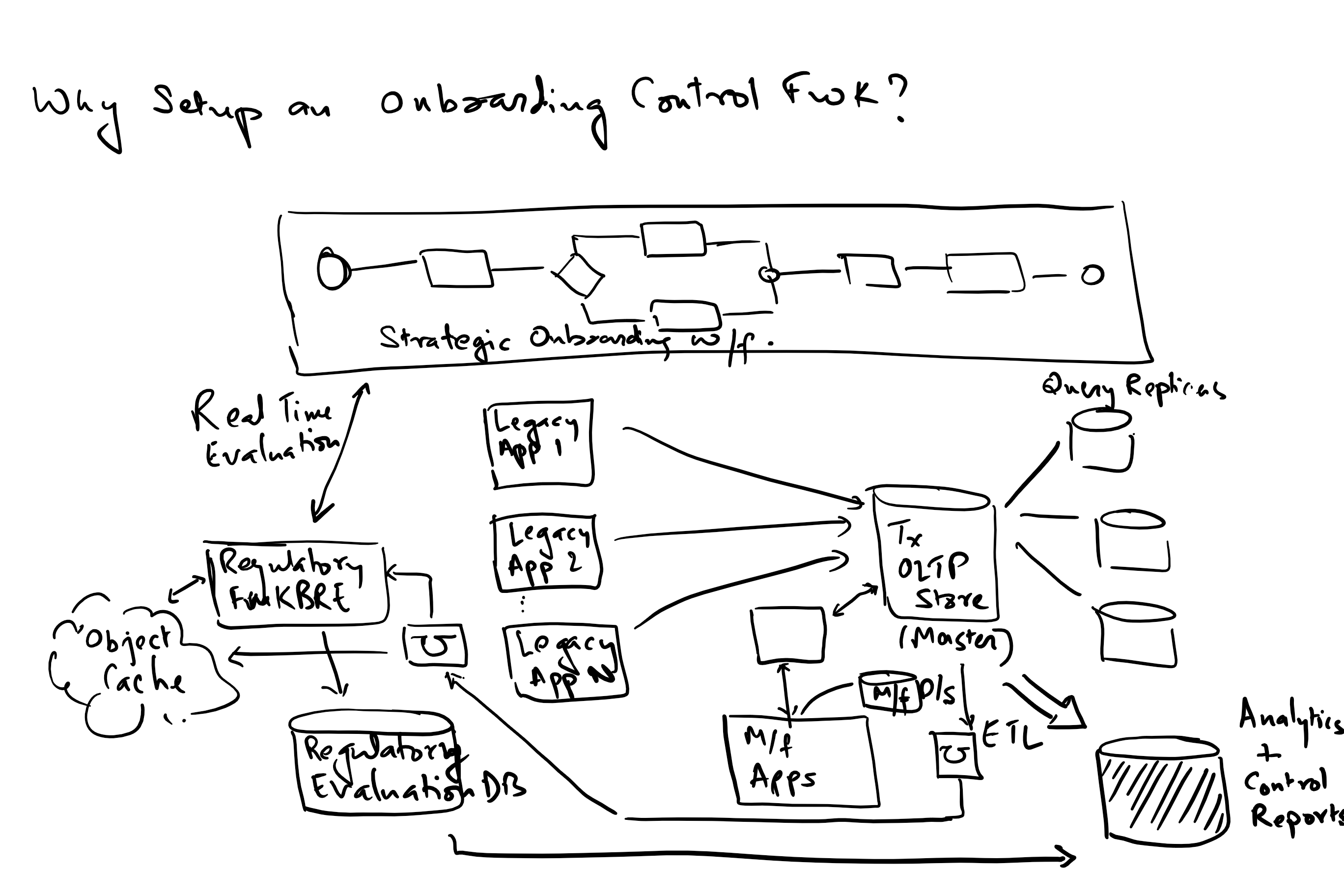
How do big data patterns complicate this exercise?

Big data introduces the following additional complexities in data processing:
1. Volume: the needs for the size of data sets to be managed and processed is usually a few orders of magnitude higher than in usual OLTP scenarios. This means additional resources, ability to scale horizontally and manage latency requirements.
2. Velocity: Needs rem time data and event handling with a view to be fast and avoid bottlenecks.
3. Variety: With data collections augmented by IOT devices in addition to the traditional data collection mechanisms, implies the need to manage text, images, audio and video.
4. Variability: data may be available in fits and starts implying the need to deal with spikes, an architecture that allows for decoupling and manage using buffers and finally the ability to maintain latency requirements.
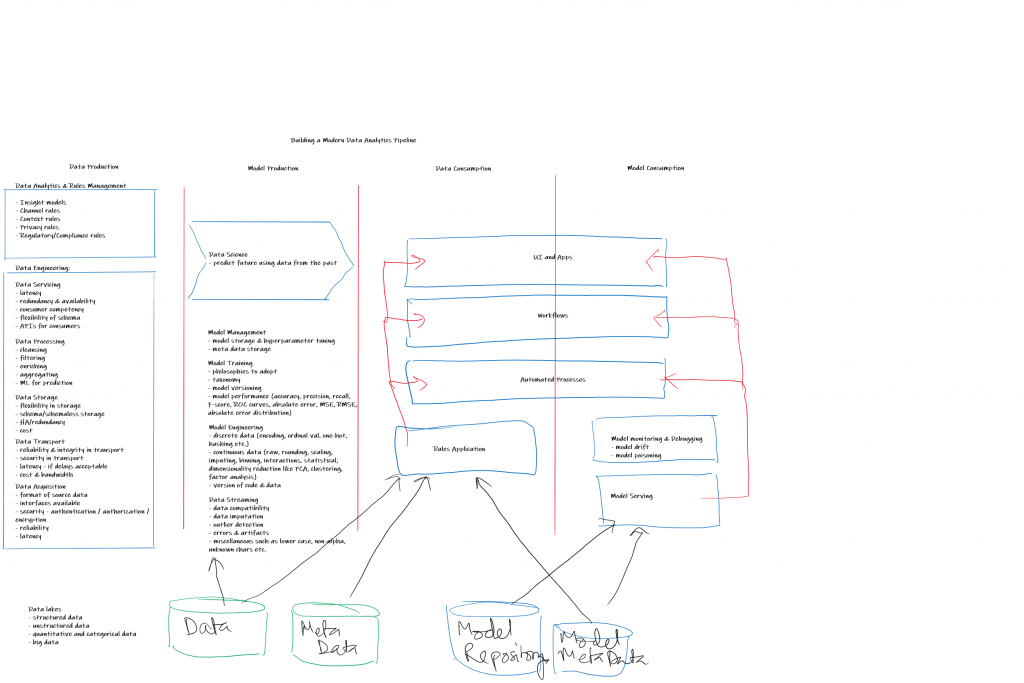
Happy to share real life experiences on the above… please reach out if there is interest.
 learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”![\[\theta=(X^TX)^{-1}X^Ty\]](https://eli.thegreenplace.net/images/math/20baabd9d33dcd26003bc44c7d81ba39e1ad4caa.png) ) Refers to a set of simultaneous equations involving experimental unknowns and derived from a large number of observation equations using least squares adjustments.
) Refers to a set of simultaneous equations involving experimental unknowns and derived from a large number of observation equations using least squares adjustments. brains (biological neural networks). Such systems learn the model coefficients by observing real life data and once tuned can be used in output predictions for unseen data or observations outside the training set.
brains (biological neural networks). Such systems learn the model coefficients by observing real life data and once tuned can be used in output predictions for unseen data or observations outside the training set. 
 Common measures that should drive an application or application development team’s metrics collection and measurement:
Common measures that should drive an application or application development team’s metrics collection and measurement: