


Future of On-boarding Systems at Banks and Financial Institutions

Why On-Boarding Applications Require A Consistent Framework?
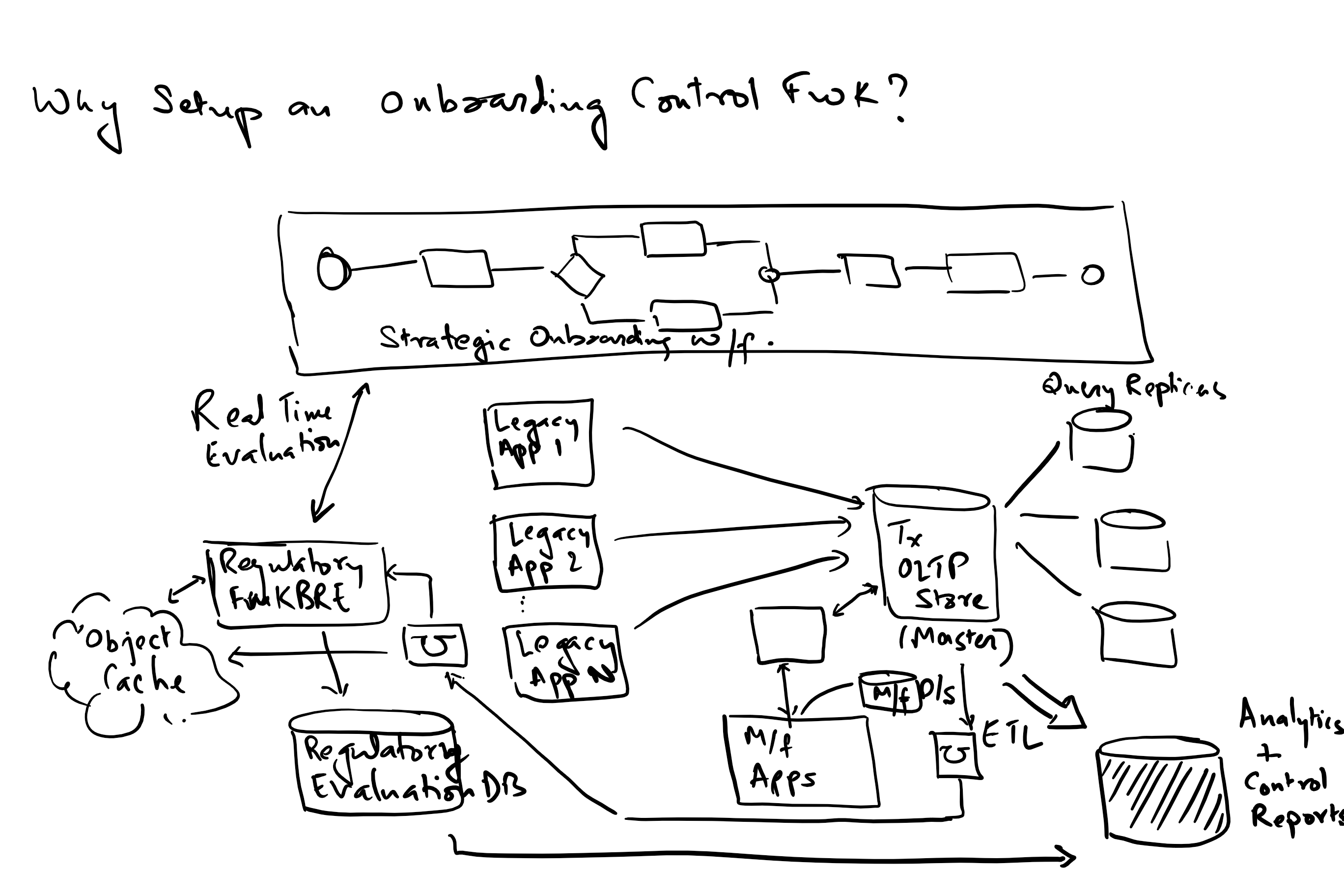
My bank has been trying to solve on-boarding for the last 25 years via a variety of on-boarding systems. Given the vagaries of budget cycles, people’s preferences and technology choices, we ended up with over 10-15 systems that did on boarding for specific products, regions and type of clients like Commodities / FX / Derivatives / Options / Swaps / Forwards / Prime Brokerage / OTC Clearing etc. With increased regulations especially FATCA (which I was hired to implement) meant wasteful and fractured capital expenditure in retrofitting each of these 10+ systems to be compliant with regulations.
To address this, I made the case for going to a single on-boarding platform, where we could maximize feature reuse, optimize investment and be nimble with the capabilities we were rolling out. I refocused the team to move on boarding to this single platform called “The Pipe”. This included negotiating with stakeholders to agree on bare minimum functionality that would let them move to pipe.
Ensured that all new feature development happened only on the go forward strategic platform. Designed an observer pattern to create FATCA cases (and later every other regulatory case) only on the pipe platform regardless of where the account or client was on-boarded. This allowed for functionality on the legacy systems to be stymied and for our business to easily move over to the strategic platform.
We streamlined delivery of functionality into a regular 4-week monthly development cycle followed by a test and deployment cycle. Achieved 99+% of all new client accounts being on-boarded on the pipe platform. Created a common regulatory platform that allows for all reg cases being created on the Pipe platform regardless of where it was created/updated. We were able to streamline development to rollout a new regulatory program in a single release cycle, which otherwise would have taken a project running for a year or more to implement. This helped us rationalize investment and also provided assurance to my business around regulatory compliance;
Happy to share details around the challenges we faced and the strategies we employed to overcome them.
As always, I welcome any comments or compare notes on a similar situation that you may have come across.
Difference in motivating your team – healthcare vs. finance
You may need different techniques for motivating your team in healthcare and finance domains. Here’s some experience from the field.
In the Healthcare domain, when I was running projects in the field – we were able to connect the project outcomes to a patient’s health. For e.g. on a project where we were automating information collection (using a tablet coupled with a workflow tool – filenet) for a nurse visit for a patient infusion – we could correlate the accuracy of the data collection and the subsequent real time interventions we predicted to a reduction in ADE (Adverse Drug Events). It was certainly very motivating for the team to link the project outcomes to better patient health and the ability to save a life.
On another project “Therapeutic Resource Centers (TRC)” – this was similar to organizing our pharmacy and call center staff in a cluster of different cells specializing in a certain disease condition like cardiovascular or diabetes or neuro-psych or specialty. We were able to use a patient’s prescription history and medical claims to stratify them to a TRC. Once we achieved this, for any inbound contact from the patient for either a prescription or a phone call, we were able to route them to our appropriate therapeutic resource center cell. This resulted in a much more meaningful conversation with the patient regarding their health including conversations about adherence and gaps in therapy that had a direct impact on patient health. We were then able to use actuarial studies to prove the value of this model and introduced innovative products in the market to drive mail order dispensing at a much higher rate within our drug benefit plans to employers and health plans while promising for an overall reduction in healthcare spend and patient health.
In the finance domain its a lot harder to connect the outcomes of your projects to a fulfilling objective like patient health. Instead I have used a couple of different techniques to motivate my teams –
Close engagement with the business working with the regulators to understand the impact of their work. For example when we ran the risk ranking project, what motivated the team was their working very closely with the business in being able to visualize our regulatory rules and to be able to easily explain why we arrived at the result we had. What was motivating was also the fact that my team had come up with a way of visualizing the rules, that the business had not experienced before. We also were able to provide a complete audit history of how the risk ranking had changed over time by using a bi-temporal model to store our evaluation results and reason codes and the change in which client characteristics led to our evaluation of a different risk metric for the client. The business was a lot more comfortable in our annual sign offs after this visualization of the rules and audit records being available when ever we needed them for a regulatory audit.
A second way that I have used for motivating my team is being able to tie in the flexibility of our systems to the rapid changes in the regulatory landscape. Once we have a good design in place – that was able to extract our business rules out of the bowels of a program, these became a lot more accessible to change outside of the usual code release window. We were able to change our rules using a separate change cycle as opposed to our regular monthly or quarterly code release cycle – and be able to change things like high risk jurisdiction countries at a much faster pace (as needed and approved by the business). Being able to tie in our design to reduction of capital needed for our projects and also having to avoid the rapid code changes into production for every rule change definitely helped team morale as they were not constantly supporting emergency changes related to a rapidly changing regulatory landscape.