


Future of On-boarding Systems at Banks and Financial Institutions

Why Is Building a Trust Bridge Critical at Technology Inflection Points?

How can you relate ML algorithms to your business?




Evolution Of AI And The Trust Frameworks We Need to Support It

We have seen evolution of AI systems from the simple to the more complex: Going from simple correlations and causations, to model creation, training and advanced prediction to finally unsupervised learning & autonomous systems.
Trust Models Required At Each Stage Of Evolution
Human society has been seen to be comfortable with assigning accountability to one of its own i.e. a human actor who creates, authors or mentors these models and can assume accountability & responsibility. If you trace the evolution of our justice systems from the time of Hammurabi (sixth king of the First Babylonian Dynasty, reigning from 1792 BC to 1750 BC), to the modern ones in nation states today, we seem to accept good behavior within a well defined system of laws and rules, and digression from these attract punishment which is meant to drive compliance.

{kind=link}
But will this always be true? Do we need new trust models and enforcement mechanisms?
Some Questions To Answer Before Advent Of Completely Autonomous Systems:
How do you program ethics?
Morals are the objective transcendent ideals we base our ethics upon. Jonathon Haidt in his exploration of the conservative and liberal morality describes 5 key traits – harm, fairness, authority, in-group and purity. Per his TED talk, liberals value the first two and score low on the other three, while conservatives value the latter 3 more than liberals.
Ethics are the subjective rules by which we govern our behavior and relate to each other in an acceptable manner. So which of these moral principles and in what measure should our ethical rules be based upon? And who chooses?
These ethics rules determine the system’s behavior in any situation and thus form the basis for the trust system we will operate upon with the autonomous system. (See the definitions of trust in my earlier post here)
Would the creator of a model be held responsible for all its future actions?
Think about an infant that is born. He/she usually has a base set of moral frameworks hard wired into the brain and it is life experiences that shape how that model further develops, what behaviors are acceptable in society, which ones are not, what’s considered good vs. evil etc. The only thing that a creator can be held responsible for is the base template that he inputs into creating the autonomous AI system. Anything that is learnt post birth would be a part of the nurture argument that would be very difficult to assign accountability for.
Can you set up a reward and punishment system for AI models?
If we consider an AI system to be similar, how do you provide a moral compass to it? Would you expose it to religion (and which one?) to teach it the basics of right or wrong or set up reward and punishment systems to train it to distinguish desirable vs. undesirable behavior. And again who determines what is desired and what is not – is it us humans or do we leave this up to the autonomous AI system.
Who decides on when and how we go to Autonomous AI?
When would we as a society be ready to take the leap? There are a number of thought leaders who have warned us about this including Stephen Hawking and Elon Musk. Are we ready to heed those warnings and muzzle our explorations into truly autonomous systems or is this an arms race that even if we bore restraint, someone somewhere may not act with the same constraints that we did…and finally was the purpose for us as a species was to develop something more intelligent than us that is able to outpace, out compete and eventually sunset our civilization?
I guess only time will tell, but meanwhile it is important to at least model ethical rules as we know it (similar to Isaac Assimov’s three Laws of Robotics – A robot may not injure a human being or, through inaction, allow a human being to come to harm. A robot must obey orders given it by human beings except where such orders would conflict with the First Law. A robot must protect its own existence as long as such protection does not conflict with the First or Second Law) into systems and autonomous programs that we create but realize that our biases, desires and ambitions will always be a part of our creation…

A Possible Way Forward…
We need a framework to establish certain base criteria for evolution of AI – something that will be the basis of all decision making capabilities. This core ROM which cannot be modified should form the basis of trust between humans and autonomous AI systems.
This basic contract is enforced as a price of entry to the human world and becomes a fundamental tenet for trust between us humans and autonomous systems allowed to operate in our realm.
As long as humans trust the basis of decision making upon these core principles (like Assimov’s three laws of robotics described above) we will operate from a position of mutual trust where we should be able to achieve a mutually beneficial equilibrium that maximizes benefits all around.
Given the CRISPR announcement today about two babies being born with their genes edited using CRISPR Cas9, its all the more urgent for us to establish this common framework before the genie is out of the bottle…
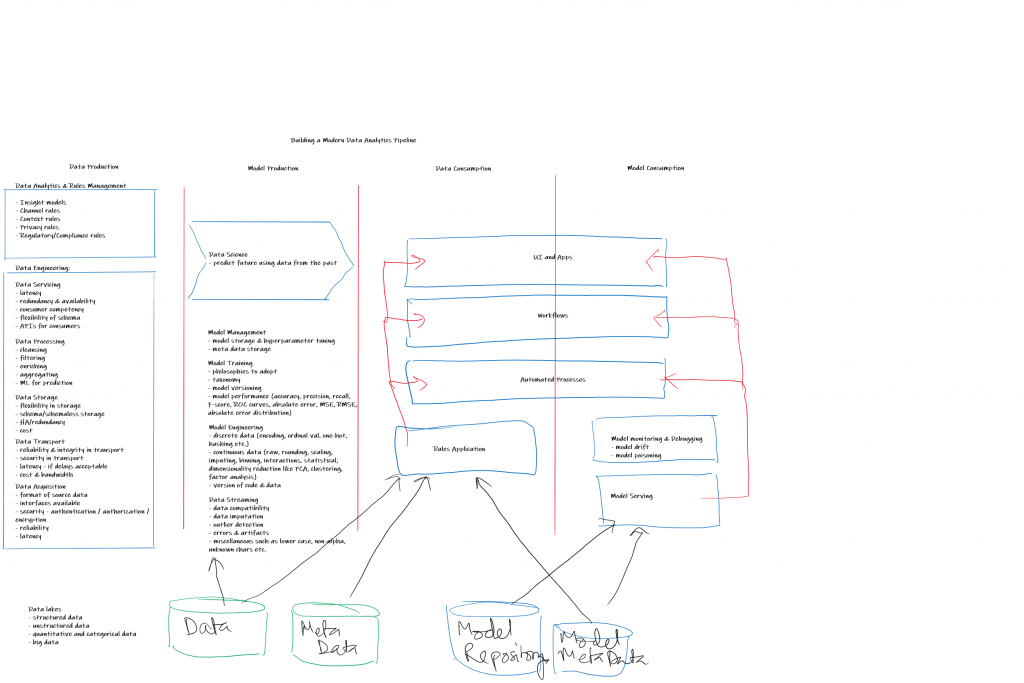
Setting Up a Data Science Platform

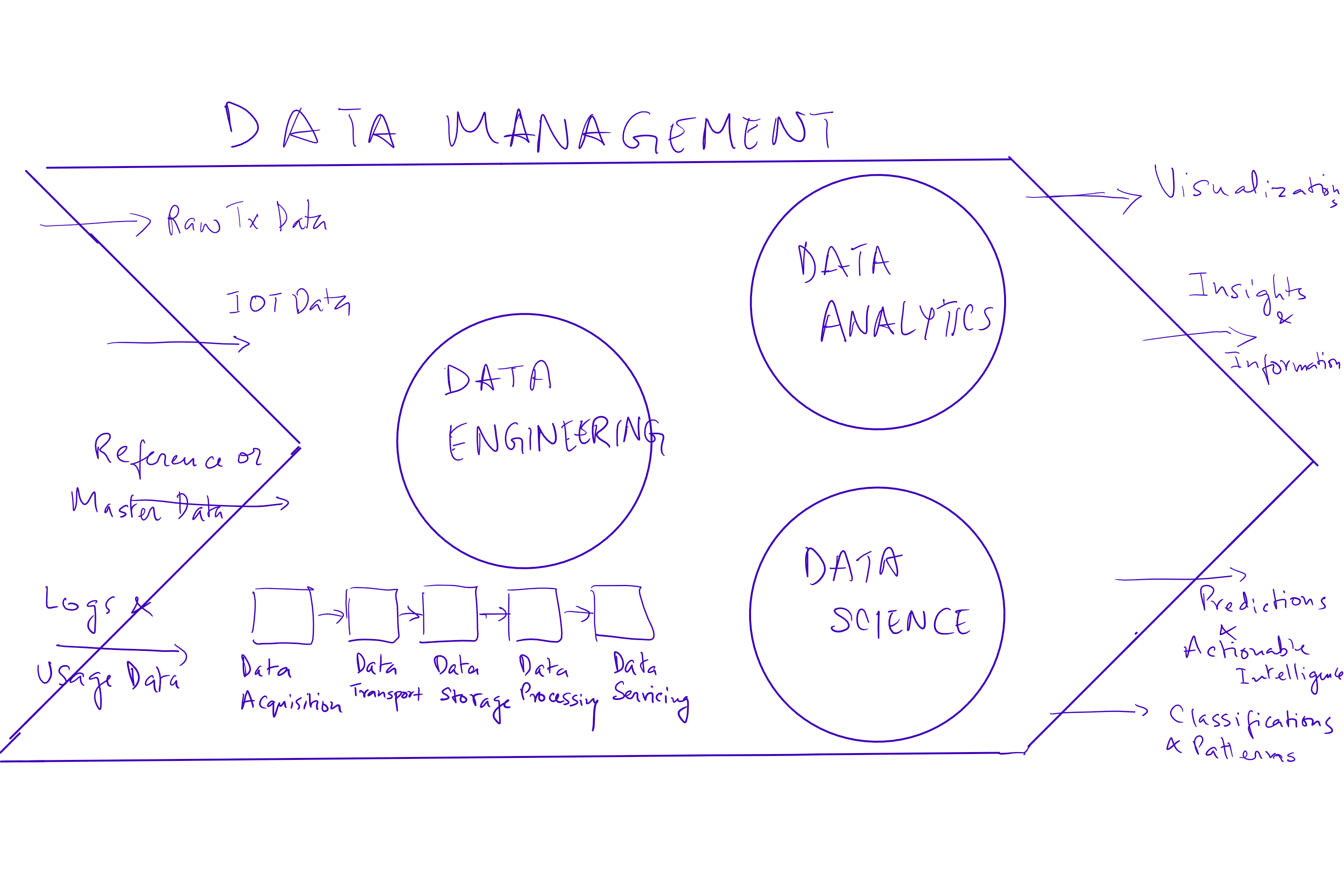
What is a Data Science Platform?
It’s a platform that allows for data collection, extraction, storage, exploration, visualization, inference & analytics and ultimately modeling to provide predictions and classifications.
 Why do you need a data science platform and what do you plan to achieve from it?
Why do you need a data science platform and what do you plan to achieve from it?
Usually the business need is to predict the future and establish causation. In order to predict the future one must determine independent and dependent variables, causation vs. correlation and thus come up with models that allow for predicting what the future will be when we tweak certain causative factors.
What are the key elements needed?
There are mainly three key elements of data management –
1. Data engineering – is the set of practices that convert raw data to processed data by building data pipelines, applications and APIs. This process is concerned with how data is captured, moved, stored, secured, processed (transformed, cleansed and aggregated) and finally utilized.
The different stages within data engineering are:
Data acquisition is the process of acquiring data with concerns around the format of source data, existing interfaces that are available or new ones that have to be built, security (including authentication, authorization and encryption), maintaining reliability and finally latency.
Data transport manages reliability and integrity in transport, security, latency and costs and bandwidth.
Data storage deals with the flexibility in storage, choices around schema and schema less storage, high availability and redundancy and cost of storage.
Data processing deals with transformation, cleansing, filtering, enriching, aggregating and machine learning models for prediction.
Finally, Data Servicing is the availability pattern to end consumers of the data, dealing with latency, redundancy and availability, consumer competency in understanding and utilization of these data sets, flexibility of schema and ultimately the APIs for consumer applications.
2. Data Analytics – Is the practice of using the data produced by data engineering to convert it into insights and information. The tools we currently use in this space are Tableau and Qlikview reporting packages.
3. Data Science – Ability to use analytics and insights to predict the future using data and patterns observed in the past. The work includes integrating and exploring data, building models using such aggregated data, extracting patterns in past data and finally presenting results either through reports or model-powered applications. Some of the key tools we have used on our platform are Jupyter and RStudio for ongoing algorithm development, Spark for distributed execution and Kafka for messaging and data acquisition.
How do big data patterns complicate this exercise?

Big data introduces the following additional complexities in data processing:
1. Volume: the needs for the size of data sets to be managed and processed is usually a few orders of magnitude higher than in usual OLTP scenarios. This means additional resources, ability to scale horizontally and manage latency requirements.
2. Velocity: Needs rem time data and event handling with a view to be fast and avoid bottlenecks.
3. Variety: With data collections augmented by IOT devices in addition to the traditional data collection mechanisms, implies the need to manage text, images, audio and video.
4. Variability: data may be available in fits and starts implying the need to deal with spikes, an architecture that allows for decoupling and manage using buffers and finally the ability to maintain latency requirements.
Happy to share real life experiences on the above… please reach out if there is interest.
Trust In The Digital World

With the recent news of numerous data breaches and companies caught with questionable business/technology practices for managing customer data (which may seem to be in breach of public trust); the question that comes to one’s mind is how important is “Trust”? How much should you invest in maintaining trust in a proactive manner and what is the cost of “breach of trust”? How do you recover from a breach? What foundational elements of trust are damaged from such a breach? And borrowing a marketing slogan from the MasterCard Priceless campaign, is it fair to say – “Not having your company’s data breach on the front page of the Wall Street Journal: Priceless”.
Let’s look at some basics…
What is Trust?
A few definitions that I have found most relevant –
Paraphrasing, social psychologist Morton Deutsch:
Trust involves some level of risk, and risk has consequences with payoffs being either beneficial or harmful. These consequences are dependent on the actions of another person and trust is the confidence that you have in the other person, to behave in a manner that is beneficial to you.
Patricia Jenkinson, Professor of Communications at Sacramento City College defines the various overlapping elements of trust as follows –
♦ Intent to do well by others
♦ Character – being sincere, honest and behaving with integrity
♦ Transparency – open in communication with others and not operating with hidden agendas.
♦ Competence / Capacity – ability to do things
♦ Consistency / Reliability – keeping your promises, meeting your obligations
Trust is important for us to feel physically and emotionally safe. With more trust, we can effectively and collaboratively work together towards common goals by sharing resources and ideas. When trust is high, we openly express thoughts, feelings, reactions, opinions, information and ideas. When trust is low, we are evasive, dishonest and inconsiderate.
There are two basic types of trust: Interpersonal with regards to one’s welfare with privileged information and relational commitment and task oriented with its dimensions of ability to do the task and the follow through to finish the task.
Evolution of Trust
Yuval Noah Harari in his book Sapiens, describes “cooperation in large numbers” to be one of the key factors for human success over other species (which were physically stronger and much more adept at surviving the extreme elements of the earth’s environment). Trust allowed us to cooperate in large numbers and collectively gave us the ability to accomplish tasks beyond the capacity of a single individual. Chimpanzees also cooperate, but not in large numbers like humans which limits the capability of the clique.
Trust Platforms
With the advent of the digital age and large virtually connected social networks, our paradigms of digital trust have changed substantially. Rachel Botsman of Oxford University in a series of TED talks describes the transition from hyperconsumption to collaborative consumption, the evolution of trust from local to institutional to distributed.
This evolving distributed trust platform has three foundational layers (described as the Trust Stack by Ms. Botsman) – which allows us to trust relatively unknown people –
♦ Trust the Idea
♦ Trust the Platform
♦ Trust the other user
When there is assurance of accountability for a users’ actions as enforced by the platform (which has the ability to restrict future transactions by that user for bad behavior), there is implicit trust that the platform lends to transactions between complete strangers such as a transaction on the Uber or Air BnB platforms. One of the illustrative examples is how people behave differently (say cleaning up their room) when staying at a hotel vs. with an Air BnB host. In the former the expectation is that the institution will not hold them accountable for bad behavior while in the later the platform enforces this through mutual feedback and social reputation for both the guest and the host enhancing trust and ensuring good behavior.
Per Ms. Botsman, this is just the beginning, because the real disruption happening isn’t technological. It is fundamental to the way we will transact in the future. Once a trust shift has happened around a behavior or an entire sector, you cannot reverse this change. The implications here are huge.
A Simple Experiment
Daniel Arielly, a professor at Duke, in his TedX talk at Jaffa, describes a very nice social experiment. Suppose in a model society, everyone is given $10 at the beginning of the day – if they put this money in the public goods pot, then at the end of the day everything in the pot is multiplied by 5 and equally divided. So for example, if 10 people in a society were given $10 every morning and they put everything in the public goods pot, the pot would have $100, when multiplied by 5, would result in $500 at the end of the day and every one would get $50 back at the end of the day and everyone is happy. If the next day one person cheats, everyone except that person put in the $10 at the beginning of the day, there would be $90 in the pot. At the end of the day, the pot would have $450 and everyone would be returned $45 back. Everyone would notice that they did not get the full $50 back and the person who betrayed the public trust has $55. Dan’s next question was – what would happen the next day – no one would contribute to the public pot. His point being most trust games play out as a prisoners delima with a very unstable equilibrium where everyone contributes/cooperates and a stable equilibrium where no one contributes/cooperates. To maximize overall benefit, one has to ensure that everyone cooperates, and a single defection would ensure the overall benefit from cooperation going down. The moral of the story is that “Trust” is a public good, and an incredible lubricant for society. When we trust, everyone is better off, and when people betray the public trust, the system collapses and we are all worse off.
In Conclusion
A number of companies have used transparency and a persistent reputation as a mechanism to keep people from betraying the public trust for example eBay, Air BnB, Uber etc. The cost of betrayal on these platforms is that the betrayer would not be able to transact on the platform anymore because of a hit to his/her reputation.
Also adding punsihment and revenge to the mix also changes the game. A reputation for being revengeful will prevent the first player defecting. The justice system and police are a common example of using punishment to keep the trust in society.
For companies that build trust platforms that allows for even strangers to transact, a betrayal of trust by the platform is much more damaging than a transgression by a single user on the platform. With such a breach there is the real possibility of users moving to the extremely stable equilibrium of not cooperating & thus abandoning the platform (loosing network scale is an existential threat) and moving them back to cooperating and using the platform is a herculean task.
No longer can we rest on our laurels by just calling ourselves trust worthy without redesigning our systems, process and people to be transparent, inclusive and accountable.
So remember, protect the idea first, then the integrity of the platform and then individual issues or breaches that may impact trust. Once trust is broken, it’s very hard to rebuild or repair.
Therapeutic Resource Centers
We introduced a product called Therapeutic Resource Center at Medco in 2007/8. It was an extremely innovative product that was soon copied by most of our competitors.
Here’s a brief history of how we developed this product.
Medco consisted of two main businesses – the PBM business which basically was adjudication of a patient’s drug benefit – which drugs would be covered, what would be on the formulary, copay a patient had to cover out of pocket when filling a prescription, how much would a pharmacy be paid, what would we bill a payer for this transaction; the second was the mail order pharmacy dispensing business. Here we asked patients on maintenance medications, to fill their prescription at mail order. A patient would request their doctor to send their prescription to our MO pharmacy. We would then fill a 90 day prescription for the same copay as a retail pharmacy for a 30 day prescription.
In 2006, we were at about 100MM prescriptions at mail order and about 765MM POS adjudications annually. To drive efficiencies, we digitized incoming Rx’s to route them to the closest mail order pharmacy location for dispensing in the most cost effective way – so a patient on the west coast had their fill done from Las Vegas while a patient on the east coast would have our pharmacy in Tampa or Willingboro fulfill their order.
Once we had the ability to digitize Rx’s, we were also able to group, sort or route to the most efficient way of doing business. We had the same ability with customer service phone calls coming in – recognizing the ANI allowed us to know who was calling and whether they had an order with our pharmacy.
Since we also had a lot of patient data (Rx, medical claims etc.), we could stratify the patient population into various disease conditions, and if we used this stratification in routing prescriptions or calls, we had the ability to route all diabetics to a group of pharmacists that specialized in diabetes, or for neuropsych patients to the neuropsych TRC. Similarly we created the Cardiovascular, Oncology, Specialty and Women’s Health TRCs.
We then discovered that our interactions with the patients were a lot more meaningful, with our pharmacists and CS representatives becoming trusted advisors to these patients. It also meant that we were able to keep patients more adherant on taking their prescriptions as well as intervene on behalf of the patients to request a gap in care intervention when we saw a missing therapy or course of actions.
Using actuarial data, we were able to establish that while this intervention was more expensive than our regular cost effective dispensing and customer service operations, we were also able to improve patient health, bend the healthcare cost curve, reduce the adverse drug events and also introduce some new genetic testing as means of either avoiding certain treatments (using a genetic test (Abnormal CYP2D6 enzyme) before prescribing Tamoxifen for Breast Cancer treatments) or adjusting the dosage on some really poisonous ones (introducing genetic tests to regulate their dosage when a patient was first prescribed warfarin (a blood thinner)).
Given that our interventions were this effective and we had data to prove it, we introduced a product called TRC in 2007, which would entitle a client’s patients to our interventions, in return for a larger mail order penetration that drove our margins on the mail order side. This really helped both improve our margins as well as improve patient care.
Medco’s Product’s & Services:
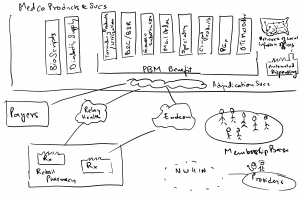
Therapeutic Resource Center Business Model:
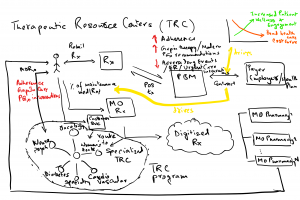
The above context diagram describes how our product worked, please do reach out if there are questions regarding how we designed this.
How Do We Transcend Our Time?
Yuval Noah Harari has a very interesting explanation for the success of human beings over other species –
- The ability to collaborate in large numbers
- The ability to weave stories i.e. be able to exist in multiple realities –
I would like to elaborate on the second point here. Think about it – the human life span is really short. How does one advance knowledge past a single human’s time scale – say a 100 years. There are two ways to transcend time –
- Encoding core information within our genome/DNA – allows for us to pass on to our progeny that certain traits have worked well to help us survive; Individuals with unfavorable genes / characteristics perish in this race for survival and with them goes the propagation of that combination of genes. A very good treatment of this is described in Siddhartha Roy’s “The Gene”
- Secondly we pass knowledge as stories (through language – verbal, written, mathematical, algebraic etc.). This allows for a child to continue to progress collection of knowledge without having to discover Newton’s laws or Einstien’s theory of relativity and build upon these fundamental tenets.
The above in my opinion has helped humans transcend time and have an impact much larger than the finite lifespan of a single human being.
We should therefore be thankful of the folklore, family stories, history that each of us is passed on by our ancestors.
Why Set Up A Data Warehouse?
What is a DataWarehouse? And why would you need one?
A data warehouse is a central repository that aggregates data from all transactional and other data sources within a firm, to create a historical archive of all of the firm’s data even when transactional systems have hard data retention constraints.
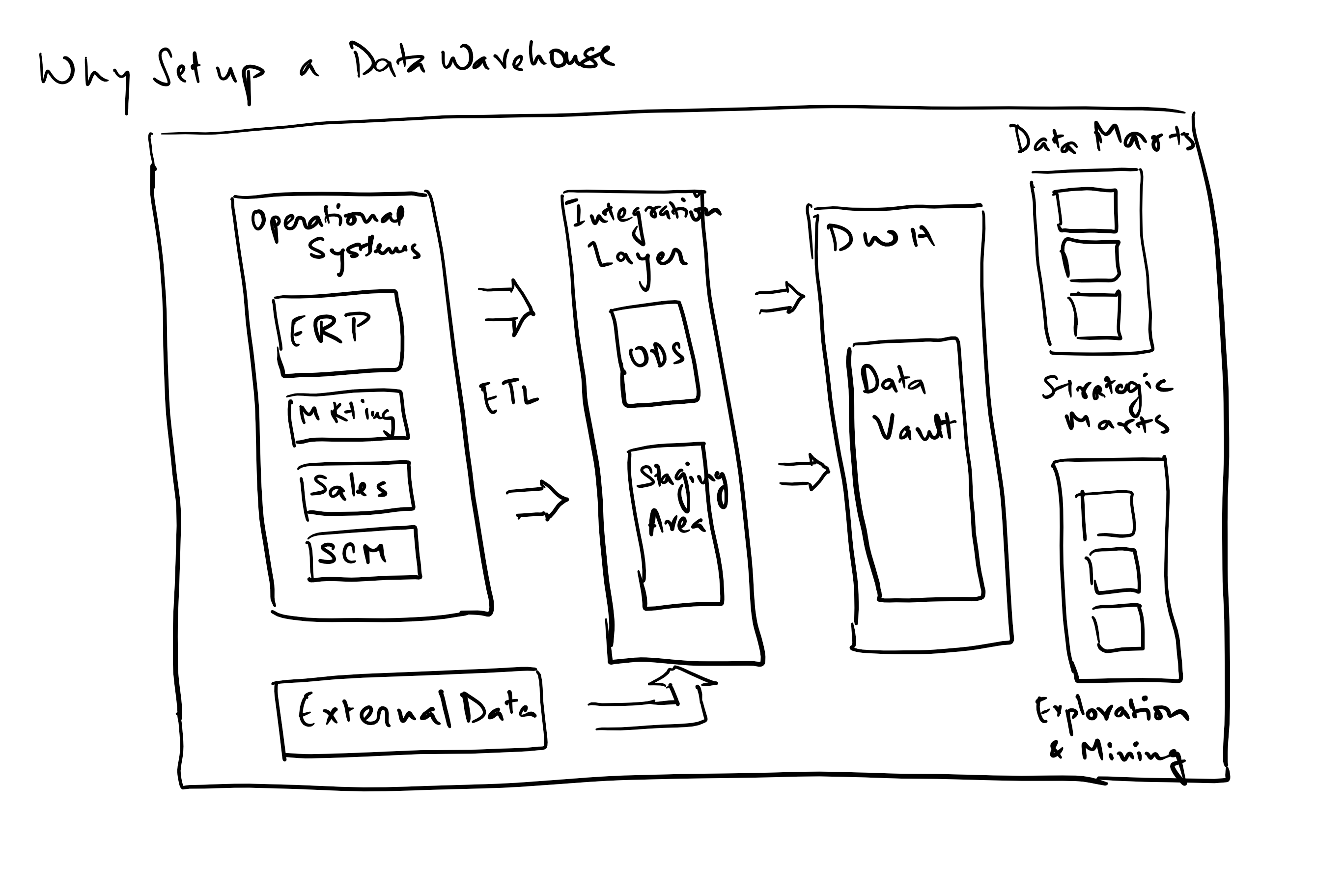
It provides for the following capabilities:
- Aggregates data from disparate data sources into a single DB; hence a single query engine can be used to query, join, transform/transpose and present the data.
- Mitigate the problem of database isolation level lock contention in transactional systems due to running of large analytical queries
- Maintain data history even when source systems do not and provide a temporal view of the data
- Ability to create trend reports comparing yoy (year over year) or qoq (quarter over quarter) performance for senior management
- Improve data quality and drive a consistency in organization information – consistent code/description/ref names/values etc. Allows for flagging and fixing of data
- Provide a single data model for all data regardless of source
- Restructure data so that it makes sense to the business users
- Restructure data to improve query performance
- Add contextual value to operational systems and enterprise apps like CRMs or ERPs.
What is an Operational Data Store (ODS)?
An ODS is a database designed to integrate data from multiple sources. It allows for cleaning, resolving redundancy and integrity checking before additional operations. The data is then passed back to the operational systems and to the DWH for storage and reporting. It is usually designed to contain atomic or low level data such as transactions and prices and also has limited history which is captured real time or near real time. Much greater volume of data is stored in the DWH generally on a less frequent basis.
Why do we add Data/Strategic Marts to most modern data management platforms?
Data marts are fit for purpose access layers that support specific reporting use for individual teams or use cases for e.g. a sales and operations data mart, or a marketing strategy data mart. Usually a subset of the DWH, and very focused on the elements needed for the purpose it is designed for. The usual reasons to create data marts are –
- Easy access to frequently needed data with contentions
- Creates a collective view for a group of users
- Improves end user response times
- Ease of creation and lower cost than a DWH
- Potential users are well defined than in a full DWH
- Less cluttered as it contains only business essential data
And finally what are Data Lakes and Swamps?
A single store of all the data in the Enterprise in its raw form. It is a method of storing data within a system or repository in its natural format and facilitates the colocation of data in various schemas, structured and unstructured in files or object blobs or data bases. A deteriorated data lake, inaccessible to its intended users and of no value is called a “data swamp”.